Ours
Abstract
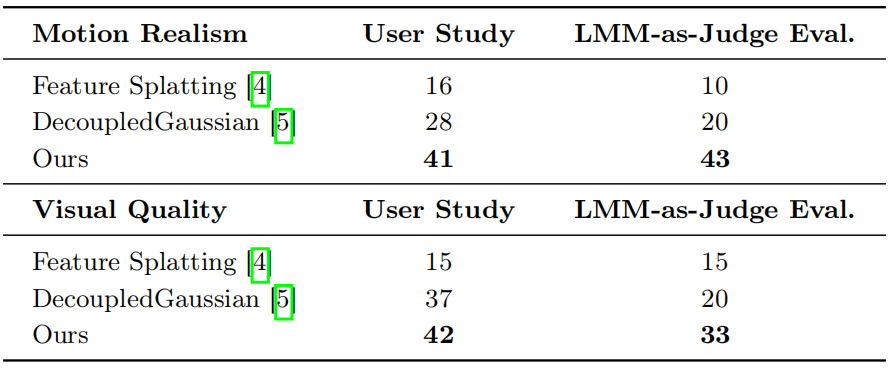
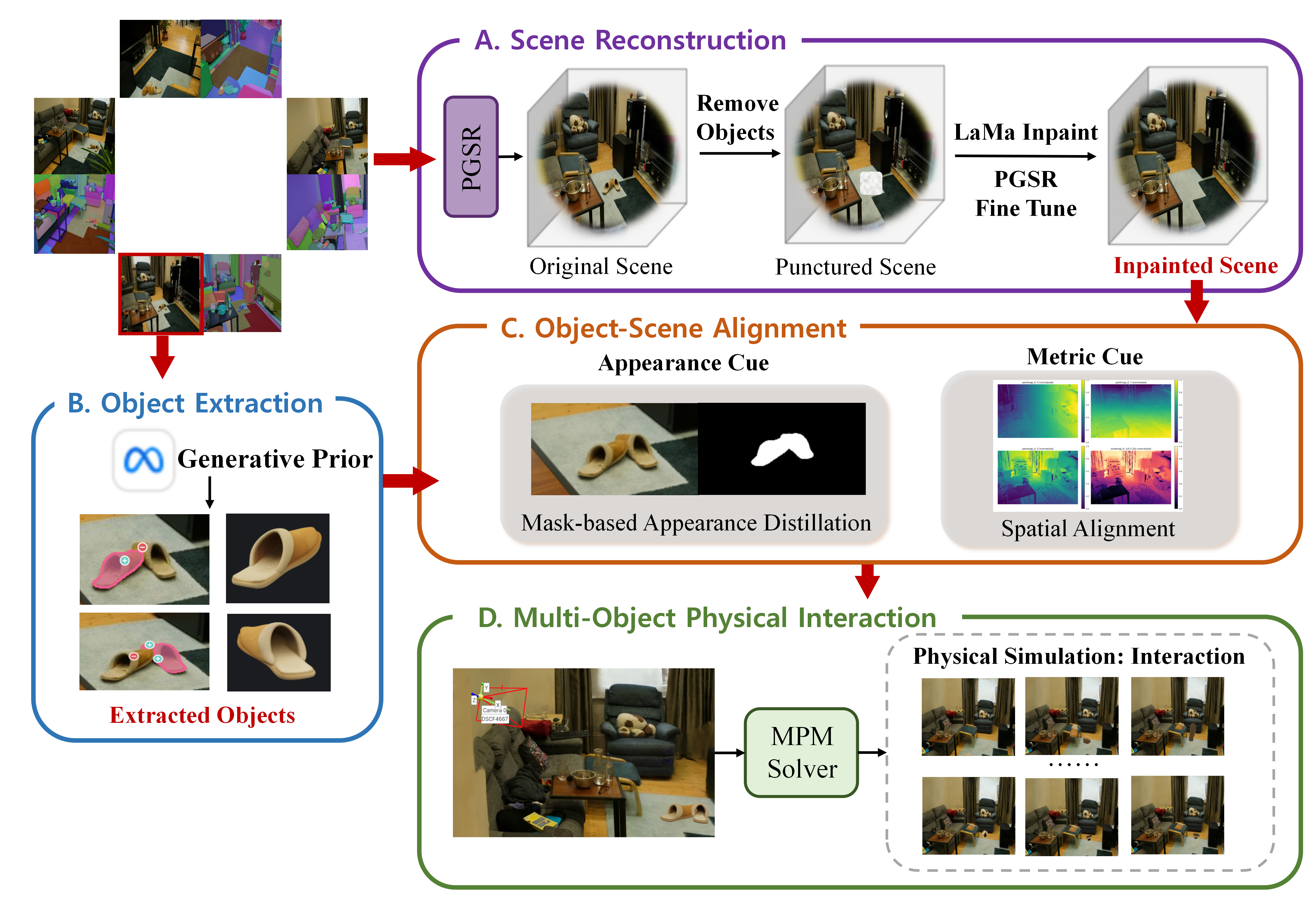
This work addresses the problem of recovering complete, simulatable object geometry from reconstructed real-world scenes, enabling physics-based interaction with objects embedded in the scene. While modern multi-view reconstruction methods can produce visually accurate environments, objects are often incomplete due to occlusions and limited observations, making them unsuitable for physics simulation. To address this limitation, we propose SAM3D-Phys, a framework that integrates scene reconstruction with generative 3D priors of SAM3D to recover physically simulatable objects. Our approach first reconstructs the scene from multi-view images to obtain scene geometry and partial observations of objects. We then leverage SAM3D to infer complete object geometry from these partial observations. To ensure that the recovered objects remain consistent with the reconstructed scene, we restore scene-consistent object states through two complementary strategies: a physics-constrained spatial optimization algorithm that iteratively aligns the recovered object to its original location, and a mask-guided appearance distillation module that refines texture fidelity based on the observed images. By recovering complete object geometry and restoring its pose and appearance within the scene, SAM3D-Phys produces clean object representations suitable for physics-based simulation, enabling simultaneous and physically consistent interactive simulation of multiple objects within a reconstructed scene.